CNN에 대해 알아보자
전통적인 CNN은 convolutional neural networks의 약자로 convolutional layer, pooling layer, fully connected layer로 이루어져 있다. convolution에 관한 내용은 이전 포스팅에서 다룬 적이 있으니 모른다면 보고오는 것을 권장한다.
https://roki9914.tistory.com/5
CNN, RNN이 무엇인지 간단하게 알아보자
CNN CNN은 Convolutional nueral network의 약자로 인공신경망의 한 종류이다. 이를 위해하기 위해서는 먼저 Convolution과 활성함수에 대해 이해해야한다. Convolution Convolution은 kernel을 입력벡터상에서 움직여
roki9914.tistory.com
다만 위의 포스팅에서 다루지 않은 몇개의 내용이 있어 추가 설명을 덧붙이도록 하겠다
Stride
위의 포스팅에서는 convolution을 할때 kernel이 한칸씩 움직이는 예만 들었지만, kernel이 한번에 여러칸씩 움직이도록 설정할 수 있다. 이와 관련된 값이 stride이며, 위 포스팅의 예가 stride=1인 경우의 convolution이다. stride가 2라면 아래처럼 한번에 두칸씩 kernel이 움직이게 된다.

Padding
padding은 주어진 input의 테두리값에 추가적으로 정보를 덧붙여서 output을 크게 만들어주는 것을 말한다.
또한, padding을 덧붙이면 output을 크게 만들어줄 뿐만 아니라, 추가 정보를 0으로만 채우는 zero padding을 해주면 테두리 정보가 소실되지 않고 output으로 전달되는 효과를 보여줄 수 있다.

Convolutional layer는 위의 convolution들과, 활성함수가 교대로 연결되는 layer이다.
pooling layer는 2x2 pooling, max pooling, average pooling등이 있는데, 자세한 내용은 이후의 포스팅에서 설명하도록 하겠다.
CNN의 전체적인 구조는 convolutional layer와 pooling layer가 feature extraction을 하면 이를 기반으로 fully connected layer가 decision making과 classification을 하는 구조로 되어 있다.
다만, 요즘은 모델의 parameter의 숫자가 늘어날수록 학습이 어렵고 generalization이 잘 안되는 문제가 있기 때문에 fully connected layer를 없애는 추세이고, 이를 위해 여러 기법이 사용되는 상황이다.
먼저 parameter의 개수를 구하는 법을 알아보자. parameter는, 우리가 학습 시작전에 지정하는 hyperparameter와 다르게, 모델이 학습하면서 배우게 되는 값들을 말한다. 예를 들어, 위의 convolution에서 kernel의 각 cell에 들어갈 각 값들이 parameter라고 볼 수 있다. 간단한 예시를 들어보자

위와 convolution을 예로 들어 계산해보자
먼저 kernel의 크기가 3x3이므로 한 층의 커널에는 9개의 parameter가 존재한다. 이때, 행렬곱을 해주기 위해서는 input channel의 channel수만큼 kernel의 층이 쌓여야 하므로 하나의 kernel은 9x128개의 parameter를 가지게 된다.
그리고 output을 보면 output의 channel은 64이다. 하나의 kernel은 output으로 channel이 1 인 output을 생성하므로, kernel이 총 64개 있어야 output의 channel이 64가 될 것이다. 따라서 paramter가 9x128개인 kernel이 64개 있으므로, 이 convolution에 필요한 parameter는 9x128x64=73728개의 parameter가 필요하다.
이러한 계산 방식을 기반으로 유명한 model중 하나인 alexnet의 parameter수를 계산해보면 아래와 같다. 빨간색은 convolution에 사용된 parameter, 파란색은 fully connected layer에 사용된 parameter이다

그림을 보면 알겠지만, convolution보다 fully connected layer에 사용된 parameter의 수가 압도적으로 많은 것을 알 수 있다. 따라서 요즘은 parameter의 수를 줄이기 위해 fully connected layer를 없애는 추세인 것이다.
parameter의 개수를 줄이기 위해 1x1 convolution이라는 것을 하기도 한다. 이를 통해 convolution layer의 channel을 줄임으로써 학습에 필요한 parameter의 개수를 줄이는 효과를 얻을 수 있다.

여기까지가 전통적인 CNN의 형식이다. 그러면, Imagenet Large-Scale Visual Recognition Challenge(ILSVRC)라는 딥러닝 모델 대회에서 우승한 모델들을 예시로 CNN에 어떤 혁명들이 일어났는지 보도록 하자. (다만, 최근의 모델은 포함하지 않았다)
1. AlexNet

위에서 예시로 들었던 모델이다. 당시에는 혁명적이었지만 지금보면 당연시되는 기초를 다진 모델이라고 할 수 있다. ReLU 활성함수를 도입하여 모델을 깊게 쌓았을때 vanishing gradient가 일어나는 현상을 막았고, GPU를 두개 사용했으며, overlapping pooling과 data augmentation, dropout등의 기법을 적용한 기념비적인 모델이라고 할 수 있다.
2. VGGNet
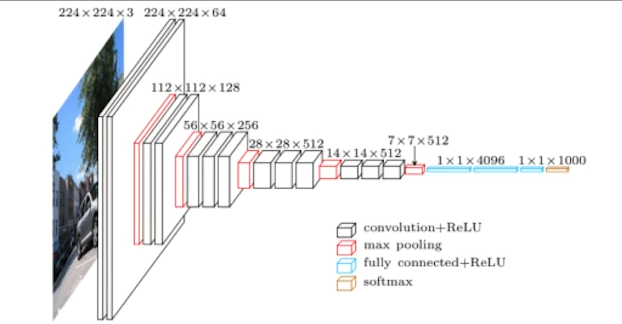
VGGNet의 특징은 3x3 kernel만을 사용해 convolution을 진행하여 parameter의 수를 줄인 것에 특징이 있다. (1x1 convolution도 사용했지만 parameter수를 줄이기 위해 한것이 아니다.)
왜 3x3 kernel만 사용한것이 parameter의 수를 줄일 수 있을까?
예를 들어 channel이 1인 input에서 똑같이 channel 1인 output으로 convolution을 한다고 가정하자.
5x5 kernel을 사용하면 25개의 parameter가 필요하게 된다. 그러나, 3x3 convolution을 두번 진행하면 5x5 convolution을 진행한 것과 차이가 없어지는 반면, parameter의 수는 3x3+3x3=18로 더 적은 paramter를 사용하는 것을 볼 수 있다.
이것이 바로 VGGNet의 특징이라고 할 수 있다.
3. GoogleNet


그림을 보면 같은 형태의 model 집합체가 여러번 반복되는 것을 볼 수 있다. 이러한 형태를 Network in Network(NiN)구조라 하며, GoogleNet은 NiN 구조를 도입했다.
또한 Inception block을 통해 1x1 convolution을 사용해 parameter의 개수를 줄이는 방법을 도입한 모델이라고 할 수 있다.
4. ResNet
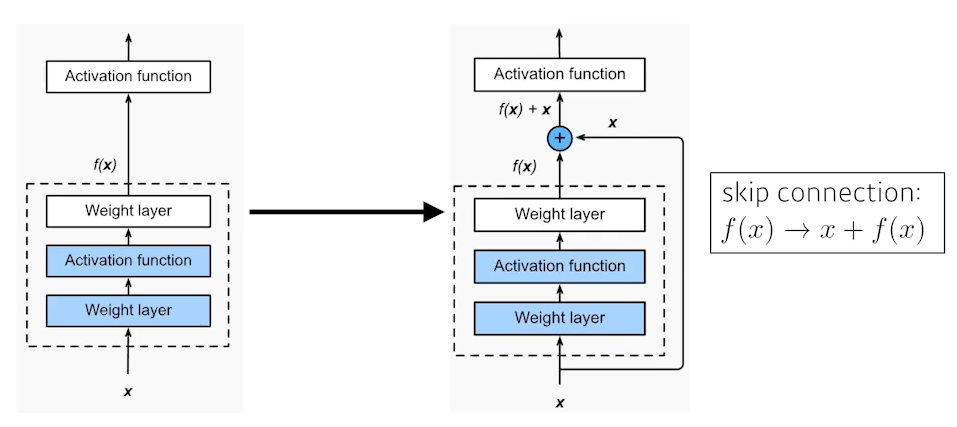
네트워크는 깊이가 깊어질수록 parameter의 수가 많아진다. 따라서 이전까지의 모델들은 너무 깊을 경우 parameter의 수가 너무 많아져 overfitting이 일어나는 문제가 있었다. ResNet은 skip connection을 통해 layer를 지나간 output 뿐만이 아닌 input값도 활성함수로 넘기는 기법인 skip connection을 도입했고, 이를 통해 깊은 layer도 학습이 잘 되도록 하는 것에 성공했다.
Skip connection의 장점은 하나 더 있는데, 기존에 AlexNet이 ReLU 활성함수를 이용해 vanishing gradient를 해결했지만 모델이 깊어질수록 다시 vanishing gradient가 발생하는 문제를 해결한 것이다. skip connection을 적용하면 모델이 깊어지더라도 vanishing gradient가 나타나지 않았다.

또한, bottleneck architecture를 통해 3x3 채널 앞뒤에 1x1 convolution channel을 더해줌으로써 input channel을 줄여 parameter의 수를 줄이는 기법도 사용했다.
5. DenseNet

Densenet은 skip connection을 할 때 resnet처럼 더하는 것이 아닌 연결을 해준다. 이때, 단순 연결만 해주면 channel의 길이가 늘어나 parameter의 수가 기하급수적으로 늘어나기 때문에, 중간에 한번쌕 1x1 convolution을 통해 channel을 줄여준다.

또한, Dense Block을 이용해 channel을 늘려주고 transition block으로 channel을 줄이는 과정을 반복한다.