Semantic segmentation과 detection은 CNN을 적용할 수 있는 대표적 분야이며, 이번 포스팅에서는 이에대해 알아볼 것이다.
Semantic Segmentation
Semantic segmentation은 이미지가 주어졌을때, 이미지 전체를 분류하는 것이 아닌, 픽셀단위로 분류를 하는 것이 목표이다. 예를 들어 자전거를 타는 사람이 찍힌 이미지가 있다면, 어디가 자전거이고, 어디가 사람이고, 어디가 배경인지 분류하는 것이다.
Semantic segmentation의 대표 분야는 자율주행으로, 실시간 도로 이미지를 보고 어디가 사람이고, 어디가 차도, 인도인지 지, 어디가 신호등인지를 구분하는 역할을 수행한다. 우리는 이를 위해 dense layer를 없애고 convolutional layer로 대체하며, 이렇게 만들어진 fully convolutional network를 도입한다.


Fully Convolutional Network는 일반적인 CNN과 비교했을 때 parameter의 수는 동일하지만 input 이미지가 커져도 학습이 가능하다는 장점이 있다. 이런경우 마지막에 출력되는 output은 하나의 값이 아닌 heatmap형태로 출력되게 되고, 이 heatmap은 deconvolution을 통해 원래 이미지의 크기로 돌아가며 semantic segmentation을 하게 된다.

여기서 deconvolution은 말 그대로 convolution을 역으로 적용하는 것을 말하는데, 여기서 주의해야 할 점은 convolution은 역계산이 존재하지 않는 다는 것이다. 예를 들어 convolution을 통해 10이라는 결과가 나왔을때 2+8인지 3+7인지를 알 방법이 없기 때문이다.
대신, deconvolution은 input에 padding을 추가 input의 크기를 늘려 ouput의 크기를 늘리는 작업을 수행한다.

Detection
Detection은 이미지 안에서 원하는 사물의 boundary box를 찾아내는 것을 말한다. 예를 들어 콜라를 들고있는 사람이 찍힌 사진이 있다면 콜라가 있는 부분이 어디인지 box로 표시해주는 것이다. semantic segmentation과 유사하다고 생각할 수 있으나, 차이점은 per pixel로 분석하는 것이 아닌 boundary box를 표시해주는 것이다.
이번에는 R-CNN 계열과 YOLO에 대해 설명해보고자 한다.
1. R-CNN

R-CNN은 input이미지에서 약 2000개의 region을 임의로 생성하고, 각각의 region을 CNN 모델의 입력 사이즈에 맞게 resize해준 후 CNN모델을 이용해 각 region의 feature를 extract한다. 그리고, 각 feature를 linaer svm을 이용해 분류한다. 그러나, 이 모델의 문제점은 처음에 임의로 생성한 2000개의 이미지를 전부 CNN을 통해 학습시켜야 하기 때문에 시간이 많이 걸린다는 단점이 있다.
2. SPPNet

SPPNet은 이미지 안에서 bounding box를 뽑고, 이미지 전체를 CNN 모델에 적용해 convolutional feature map을 얻은 후 bounding box에 해당하는 tensor만 가져오는 것이다.
3. Faster R-CNN
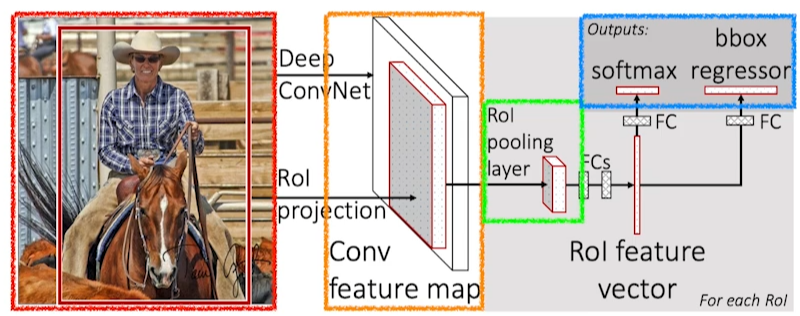
Faster R-CNN은 bounding box를 임의로 얻지 않고, bounding box를 선정하는 것 조차 network를 통해 학습한다. 이를 region proposal network(RPN)이라 한다. RPN은 이미지의 각 bounding box에 물체가 있을만한지를 학습하게 되는데, 이때 anchor box라는 값을 입력해주어야 한다. 필요한 변수는 x, y, w, h(기준점과 높이, 너비)로, 정해진 크기의 boundary box들에 대해 학습을 하는 것이다.

RPN은 먼저 128, 256, 512의 3개의 region size와 1:1, 1:2, 2:1의 ratio를 가질 수 있기때문에 이들을 조합하여 9개의 parameter를 가지게 된다.
또한, anchor box를 상하좌우 어디로 움직일지를 나타내는 변수 4개가 필요하며, 마지막으로 해당 box가 쓸만한지를 판별하는(yes or no) 변수 2개가 필요해서 총 9x(4+2)=54개의 parameter를 가지게 된다.
4. YOLO (You only look once)

YOLO는 RPN을 통해 얻어진 tensor들을 labeling하는 것이 아니라 이미지를 모델에 돌리면 바로 결과가 나온다. 이는 여러개의 bounding box를 한번에 계산하기 때문이다.
YOLO는 먼저 이미지를 S x S grid로 분할한다. 그리고, 찾고자 하는 물체의 중앙이 특정 grid cell 안에 있을 경우 해당 grid cell에게 해당 물체의 boudning box의 위치와, 그 물체의 정체를 확인할 역할을 부여한다.
각 grid cell은 정해진 개수(예를 들어 5개)의 bounding box를 예측해야 하는데, 두개의 작업을 동시에 수행한다.
1. bouding box의 크기는 정해져있으며, 각 box에 물체가 있을 확률을 계산해야 한다.
2. 각 bounding box에 무슨 물체가 있는지를 확인해야 한다.
이 두가지의 작업을 동시에 수행하기 때문에 더 빠르게 작동할 수 있는 것이다.
지금까지 semantic segmentation과 detection에 어떻게 CNN이 적용됐는지 알아봤다.
'AI 기초이론' 카테고리의 다른 글
| Pooling은 무엇인가? (0) | 2023.03.31 |
|---|---|
| RNN에 대해 알아보자 (0) | 2023.03.24 |
| CNN에 대해 알아보자 (0) | 2023.03.23 |
| 여러 Optimization 기법에 대해 알아보자 (0) | 2023.03.22 |
| Pytorch Dataloader에 대해 알아보자 - 2 (1) | 2023.03.18 |




댓글